Recent success in legged robot locomotion is attributed to the integration of reinforcement learning and physical simulators. However, these policies often encounter challenges when deployed in real-world environments due to sim-to-real gaps, as simulators typically fail to replicate visual realism and complex real-world geometry. Moreover, the lack of realistic visual rendering limits the ability of these policies to support high-level tasks requiring RGB-based perception like ego-centric navigation. This paper presents a Real-to-Sim-to-Real framework that generates photorealistic and physically interactive "digital twin" simulation environments for visual navigation and locomotion learning. Our approach leverages 3DGS-based scene reconstruction from multi-view images and integrates these environments into simulations that support ego-centric visual perception and mesh-based physical interactions. To demonstrate its effectiveness, we train a reinforcement learning policy within the simulator to perform a visual goal-tracking task. Extensive experiments show that our framework achieves RGB-only sim-to-real policy transfer. Additionally, our framework facilitates the rapid adaptation of robot policies to new environments, highlighting its potential for applications in households and factories.
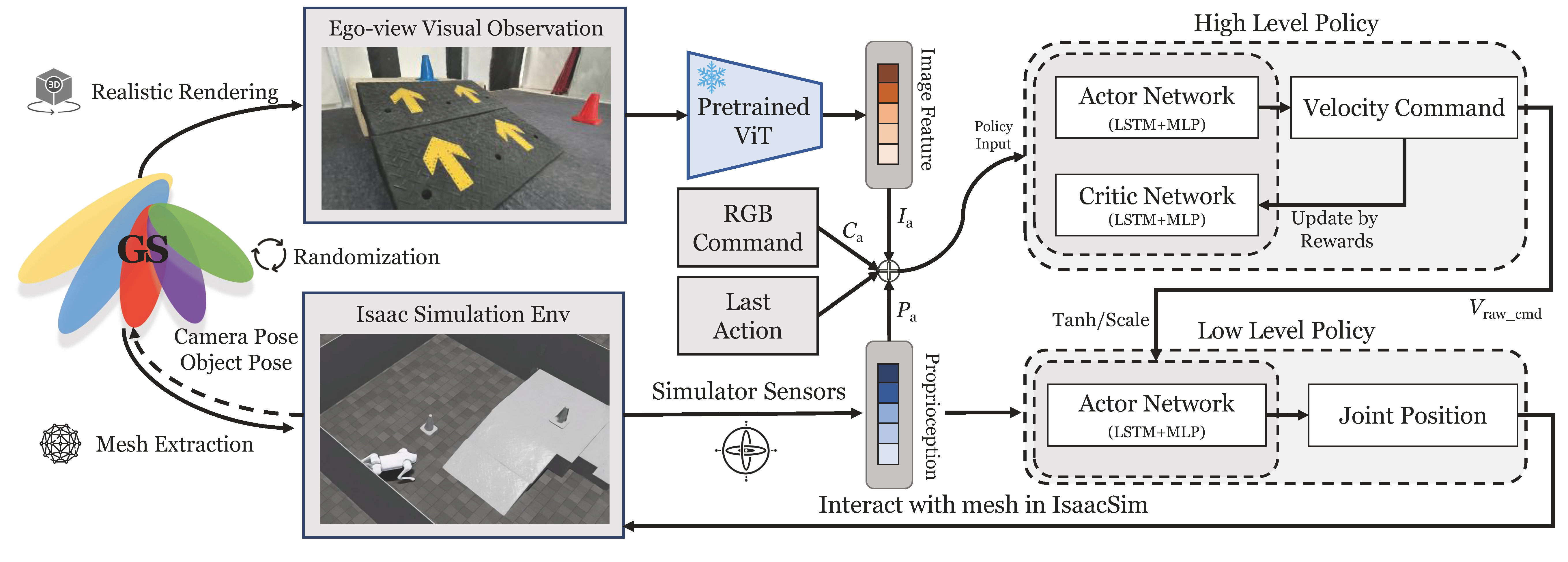
We first reconstruct the geometry-consistent scenarios from the captured images with foundation model constraints. Then we build a realistic and interactive simulation environment with GS-mesh hybrid representation and occlusion-aware randomization and composition for policy training. Finally, we zero-shot transfer the RL policy trained in simulation into the real robot for ego-centric navigation and visual locomotion.
The agent leverages the ego-view GS photorealistic rendering as visual observations and interacts with the mesh extracted from GS in the Issac Sim environment. The agent receives the RGB image feature from ViT encoder, proprioception from simulator sensors, and a task-specific RGB command as input, using an asymmetric actor-critic LSTM structure to output the velocity command for low-level policy control.
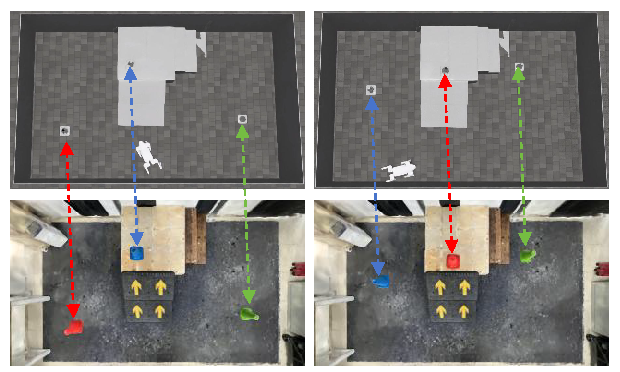
At the beginning of each episode, we randomly sample the mesh positions for the robot and three cones in the Isaac Sim environment (upper row). We synchronously merge the agent and object Gaussians into the environment and compose for joint rendering (lower row). Both mesh and Gaussian rendering results shown here are in the Bird's-Eye View (BEV) with the same camera pose.
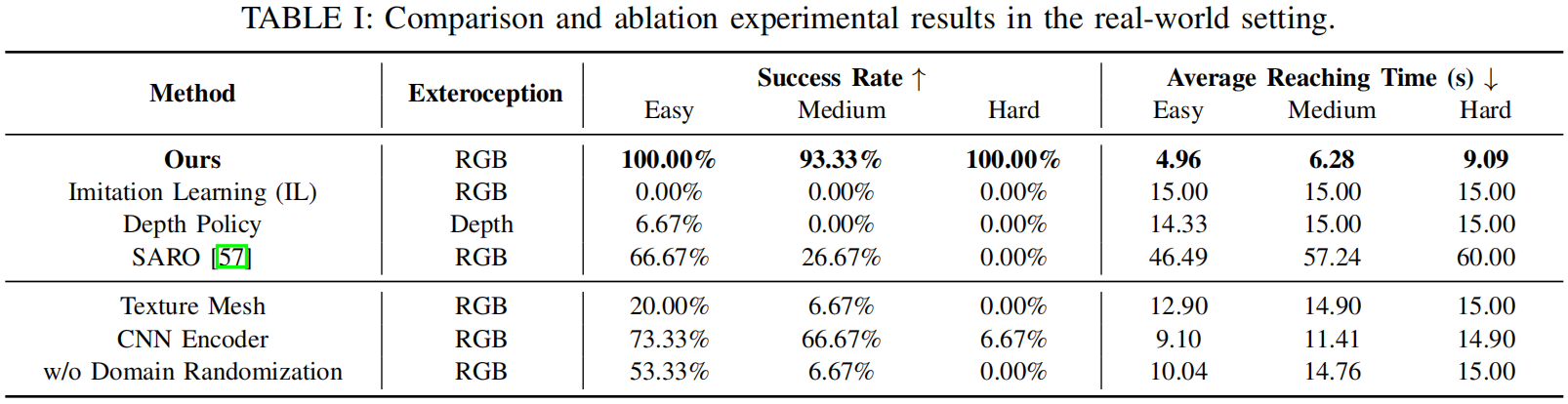
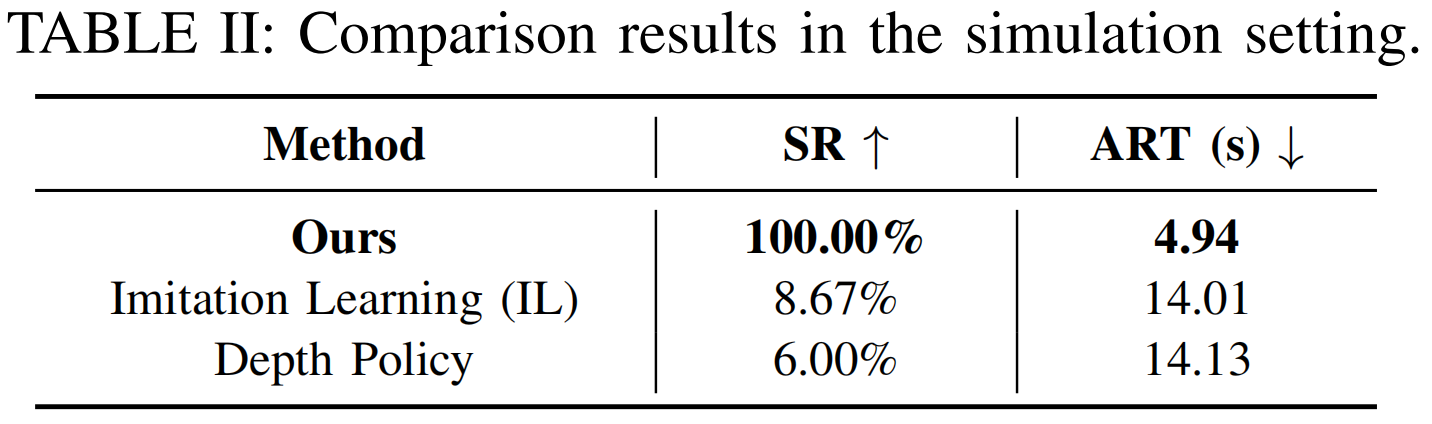
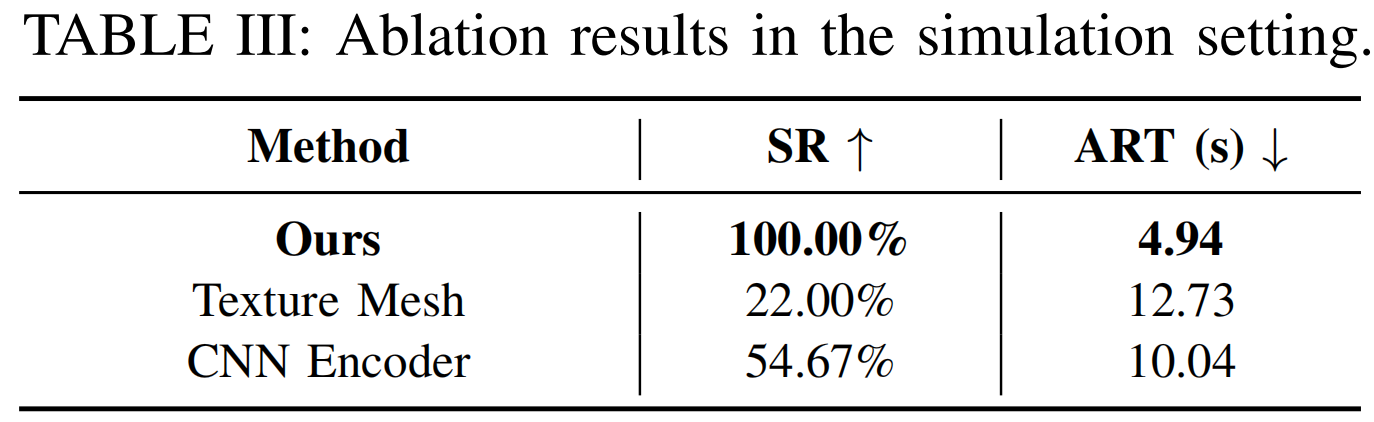
We conduct comparison and ablation experiments with various baselines.
@article{zhu2025vr,
title={VR-Robo: A Real-to-Sim-to-Real Framework for Visual Robot Navigation and Locomotion},
author={Zhu, Shaoting and Mou, Linzhan and Li, Derun and Ye, Baijun and Huang, Runhan and Zhao, Hang},
journal={arXiv preprint arXiv:2502.01536},
year={2025}
}
